Abstract
Quadrupedal locomotion over complex terrain has been a long-standing research topic in robotics. While recent reinforcement learning-based locomotion methods improve generalizability and foot-placement precision, they rely on implicit inference of foot positions from joint angles, lacking the explicit precision and stability guarantees of optimization-based approaches. To address this, we introduce a foot position map integrated into the heightmap, and a dynamic locomotion-stability reward within an attention-based framework to achieve locomotion on complex terrain. We validate our method extensively on terrains seen during training as well as out-of-domain (OOD) terrains. Our results demonstrate that the proposed method enables precise and stable movement, resulting in improved locomotion success rates on both in-domain and OOD terrains.
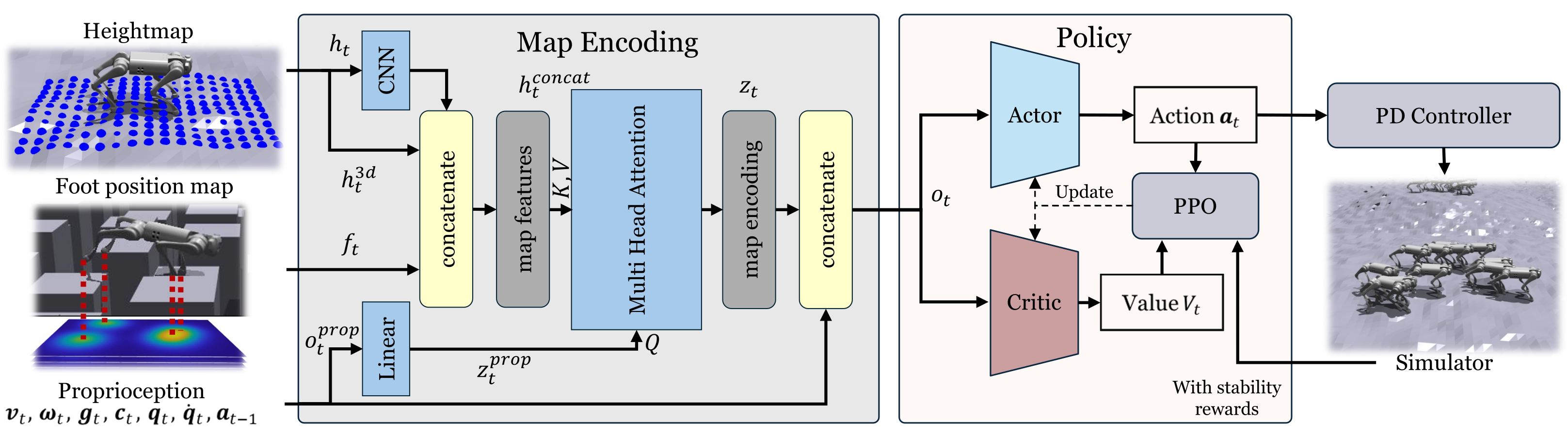
Method Pipeline
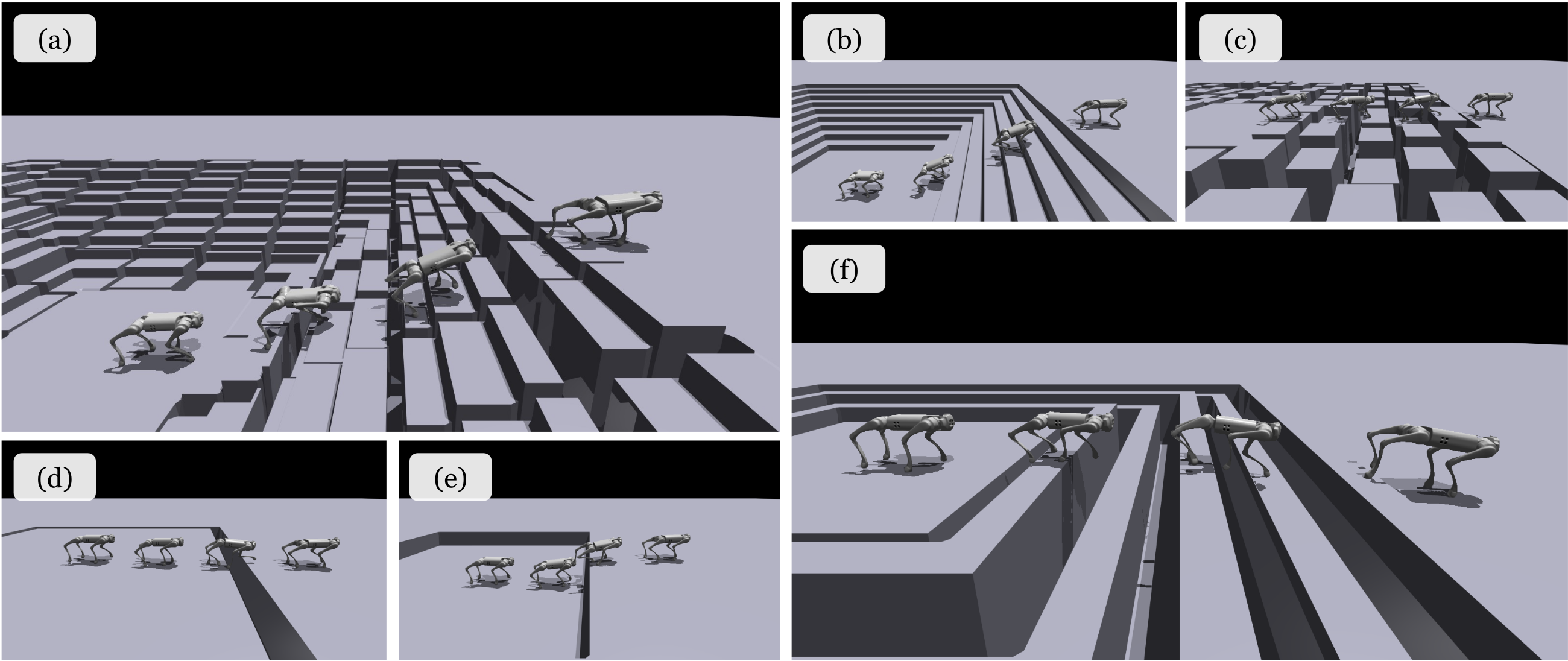
Qualitative locomotion results on OOD terrains.
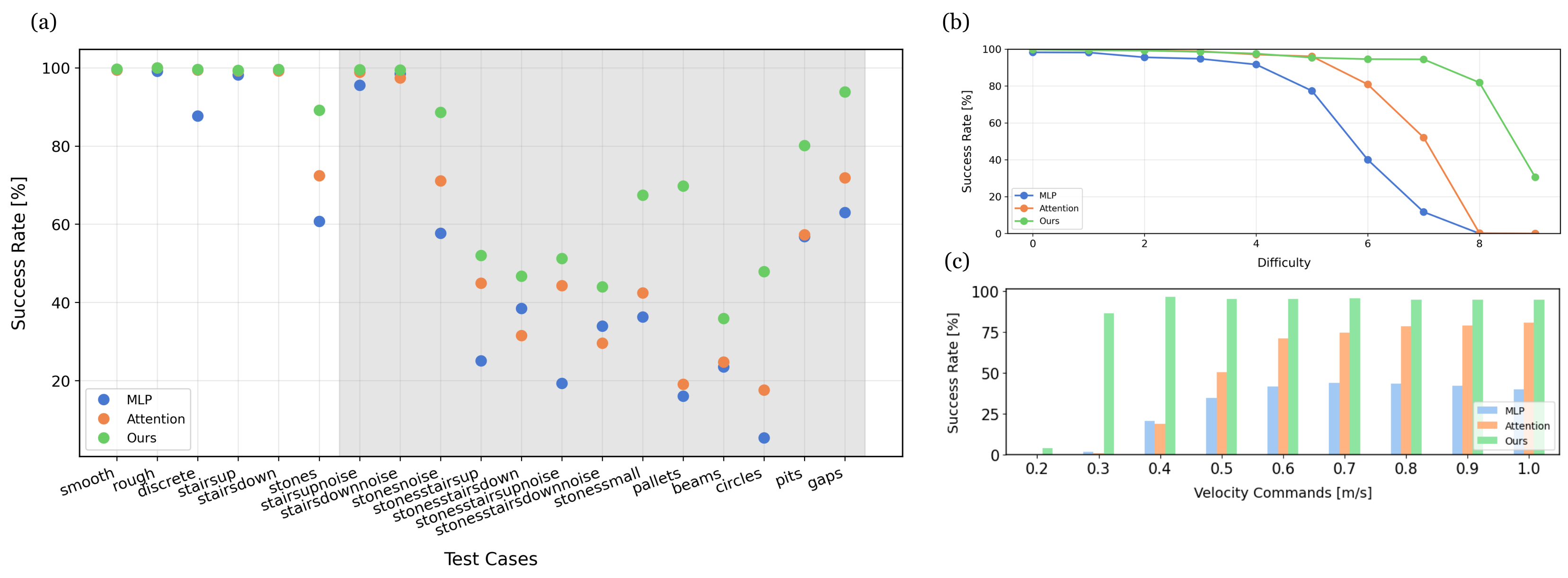
Quantitative locomotion results on a diverse set of both in domain and out-of-domain terrains.
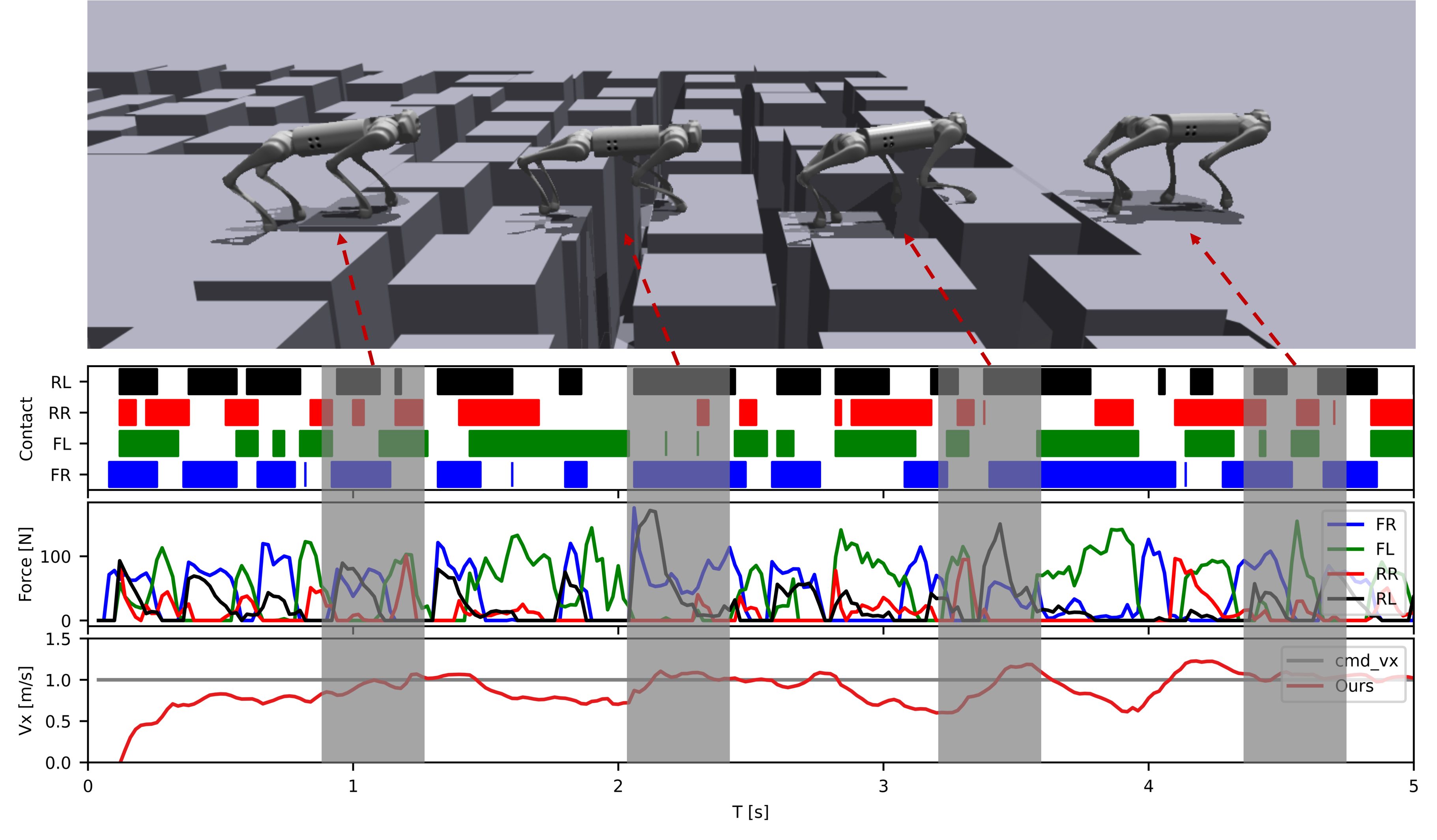
Locomotion trajectory when traversing stepping stones.
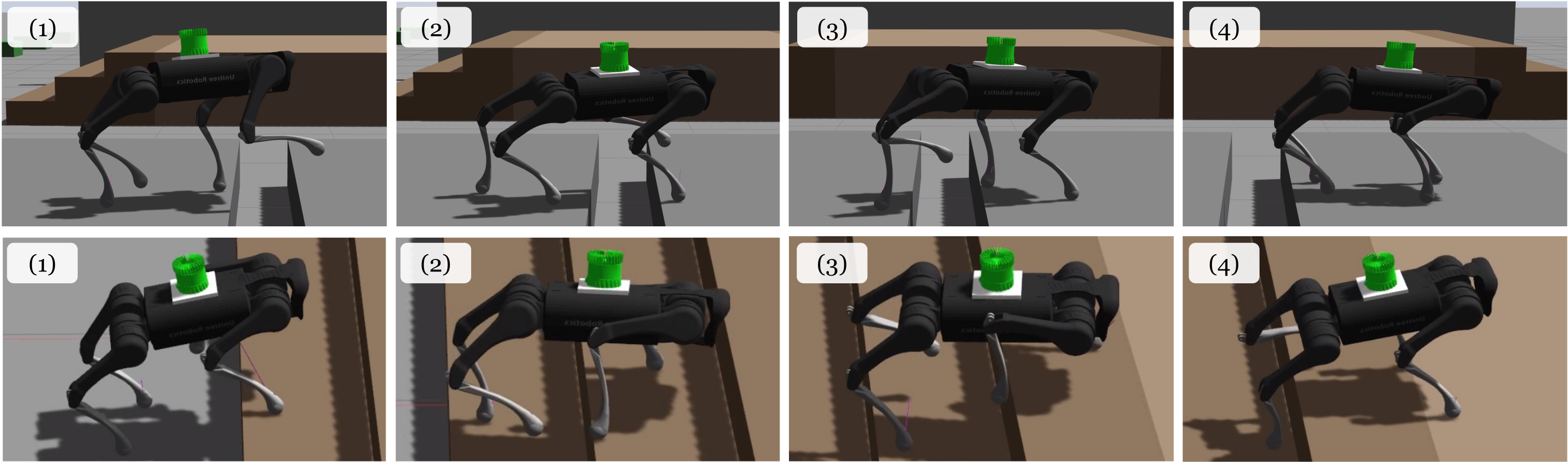
Sim-to-sim transfer from Isaacgym to Gazebo.
Locomotion Video
BibTeX
@misc{hwang2026learninglocomotioncomplexterrain,
title={Learning Locomotion on Complex Terrain for Quadrupedal Robots with Foot Position Maps and Stability Rewards},
author={Matthew Hwang and Yubin Liu and Ryo Hakoda and Takeshi Oishi},
year={2026},
eprint={2604.02744},
archivePrefix={arXiv},
primaryClass={cs.RO},
url={https://arxiv.org/abs/2604.02744},
}